Neo4j Sous Le Capot
3615-ma-vie
- Tout ce qui va suivre n’est qu’un tissu de mauvaises excuses, me
- direz-vous, mais j’ai tout de même quelques circonstances atténuantes
- quant à l’inactivité de mon blog (et mon absence de la scène parisienne
- je n’y ai pas fait de talks depuis 6 mois).
Sur un plan personnel d’abord, je suis heureux de vous annoncer qu’une jolie alliance orne désormais l’annulaire de ma main gauche :-)
Sur un plan professionnel, bien qu’absent “publiquement”, beaucoup de choses se sont passées : ma première formation sur Neo4j a eu lieu, j’ai eu l’occasion d’intervenir chez plus de clients et certains projets autour de Neo4j s’esquissent encore (stay tuned!).
D’ailleurs, si vous voulez que je vienne parler de Neo4j dans votre User Group, n’hésitez pas à me contacter (sur Twitter par exemple).
Back to business : parlons de Neo
Base de données orientée graphe ?
Neo4j, vous l’aurez compris, est une base de données orientée graphe. Mais qu’est-ce qu’“orientée graphe” signifie exactement ?
Si l’on cite Wikipedia, une base de données orientée graphe (graph database) est donc une base de données mettant en oeuvre des noeuds, relations et propriétés pour représenter et stocker de la donnée.
Cette définition peut vous paraître anodine, mais notez bien la présence de deux verbes (et non pas d’un seul) :
-
représenter
-
stocker
En termes plus techniques, une base de données orientée graphe offre donc une API (“représenter”) exposant un vocabulaire propre au graphe. Ses enregistrements sur disque (“stocker”) doivent eux aussi être formatés selon les structures d’un graphe.
Ce deuxième point est fondamental.
Prenons l’exemple d’un concurrent de Neo4j : Titan.
Dès la page d’accueil, on peut lire :
Titan is a scalable graph database […]
Support for various storage backends:
Apache Cassandra
Apache HBase
Oracle BerkeleyDB
Akiban Persistit
Cela contredit la définition que je vous ai donnée plus haut.
Si Titan était une base de données graphe, cela impliquerait que Cassandra, HBase, BerkeleyDB et Persistit le soient. Or, jusqu’à preuve du contraire, cela n’est pas le cas :)
Titan propose une surcouche d’API orientée graphe, déléguant la persistance à des stores distribuées. Cela n’en fait pas pour autant une base de données orientée graphe, tout comme Apache Giraph n’est “qu’une” API de calcul orientée graphe.
“Quelle importance ?”, me direz-vous ?
Hé bien, une base de données graphe, bien qu’elle offre des nombreux avantages, est intrinsèquement difficile à distribuer comme nous allons le voir au travers de cet article. C’est en regardant les couches les plus basses d’une base typiquement orientée graphe comme Neo4j que vous allez comprendre ce qu’être une base de données graphe implique en termes de partis pris.
Des liens et des chaînes
Neo4j, selon le modèle du Property Graph, structure les données par des noeuds liés par des relations.
-
Chacune de ces entités peut se voir attribuer un ensemble de propriétés (une clef [String], une valeur [entier, String, tableau de primitifs]).
-
Chaque relation porte obligatoirement une notion de type (exemple : une relation “FOLLOWS” ou “IS_FRIEND_WITH”).
-
Chaque noeud porte, depuis la version 2.0, une notion optionnelle (mais fortement recommandée) appelée “label” (un noeud a de 0 à n labels).
Évidemment, toutes ces informations sont persistées sur disque.
Un simple ls /path/to/neo/data/graph.db vous permettra de
constater, outre les fichiers d’indexes Lucene (legacy: répertoire
index, nouveau: répertoire schema) et les journaux de
transactions, les différents fichiers .db :
-
neostore.labeltokenstore.db -
neostore.nodestore.db -
neostore.propertystore.db -
neostore.relationshipstore.db -
neostore.schemastore.db
Ils représentent tous un “store” dédié à un type de données particulier. Passons-les en revue individuellement, en commençant par les nouveautés.
Notez que les informations à venir sont sujettes à caution : les récents travaux autour des noeuds denses ont sans doute influencé le format des fichiers décrits.
LabelTokenStore
On s’en douterait presque, ce(s) fichier(s) contien(nen)t les enregistrements de labels. Il(s) n’existai(en)t donc pas avant la sortie de la 2.0.
Ces enregistrements comprennent :
-
un ID interne (typé int en Java, donc jusqu’à 2³¹ - 1 [sauf Java 8 où on peut avoir des int de 0 à 232 - 1 mais je diverge]). chacun de ces IDs est référencé dans le fichier neostore.labeltokenstore.db.id.
-
et un nom (c’est justement la valeur que vous assignez au label : “Personne” pour le label Personne) lui-même uniquement identifié (neostore.labeltokenstore.db.names.id) et stocké dans (neostore.labeltokenstore.db.names)
Ainsi le fichier neostore.labeltokenstore.db ne comporte en fait que des
références vers les IDs internes et noms, stockés “à côté”. Notez que
cette division en fichier neostore.db.* se retrouve pour tous les
autres stores.
SchemaStore
Avec l’émergence des labels est apparu la notion de schema. Ne vous emballez pas : Neo4j n’est pas devenue une base de données normalisée. On parle plutôt d’une base de données schema-optional.
Les labels permettent de grouper des noeuds sémantiquement similaires (cela est donc complètement dépendant du domaine métier) mais rien n’empêche lesdits noeuds d’être complètement hétérogènes. Par exemple, deux noeuds peuvent partager le label Personne tout en comportant des propriétés différentes, disons, la couleur des cheveux pour l’un, la pointure pour l’autre.
Maintenant que nous avons des labels à disposition, nous pouvons même définir des contraintes sur ceux-ci : des contraintes d’unicité par exemple. Ces contraintes sont en fait appelées rules et l’ensemble de celles-ci forment le fameux schema dont je vous parlais. Ce support est assez récent et la structuration sous-jacente est encore toute simple. En effet, une rule comprend :
-
un ID interne (
neostore.schemastore.db.id) -
sa description à proprement parler (
neostore.schemastore.db)
Jusqu’ici, j’ai couvert les additions récentes de Neo4j.
Bien entendu, Neo n’a pas attendu sa version 2.0 pour être une base de données orientée graphe à part entière. Regardons ses composants centraux.
PropertyStore
À quoi servirait une base de données orientée graphe sans propriétés sur nos noeuds et relations ? Pas grand chose :-)
Ces propriétés (rappel : propriété = clef/valeur) néanmoins ne sont pas enregistrées exactement au même endroit selon certains critères :
-
neostore.propertystore.db.indexstocke la partie “clef” des propriétés -
neostore.propertystore.db.arrays, comme son nom l’indique, est dédié aux propriétés dont la valeur est un tableau de primitives ou String -
neostore.propertystore.db.stringsquant à lui se charge de répertorier les propriétés dont la valeur est une chaîne de caractères -
les autres propriétés (booléen, entier) sont stockés directement dans
neostore.propertystore.db
Chaque jeu de propriétés est propre à la relation/le noeud le contenant, les propriétés sont représentées comme des listes simplement chaînées.
NodeStore et RelationshipStore
Le voilà, le nerf de la guerre !
Commençons par les noeuds. Chaque noeud est composé d’un :
-
ID “interne” (
neostore.nodestore.db.id) -
des références à ses labels (
neostore.nodestore.db.labels{,.id}) -
une référence vers sa première propriété (l’ID interne de la propriété) et le premier noeud parmi tous ceux qui lui sont liés (le tout dans
neostore.nodestore.db)
Conceptuellement, cela pourrait se représenter ainsi (slide outrageusement et à de nombreuses reprises emprunté à Neo Technology) :
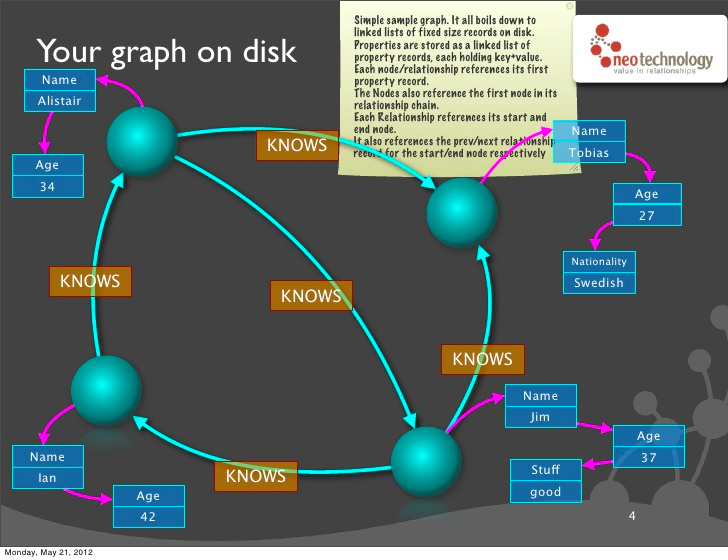
Tout repose sur la structuration des enregistrements de relations. Cela est plutôt intuitif : les relations sont l’épine dorsale du graphe.
Cet élément central se décompose de la façon suivante :
-
un ID “interne” (comme d’hab’ :
neostore.relationshipstore.db.id) -
son type (
neostore.relationshiptypestore.db.names)
Pour l’instant, ça n’explique pas ce qui en fait une base orientée graphe.
Pour cela, regardons plutôt le code Java (eh oui, c’est ça qui est cool avec les projets open source dans les langages qu’on connaît bien) :
public class RelationshipRecord extends PrimitiveRecord
{
private long firstNode;
private long secondNode;
private int type;
private long firstPrevRel = 1;
private long firstNextRel = Record.NO_NEXT_RELATIONSHIP.intValue();
private long secondPrevRel = 1;
private long secondNextRel = Record.NO_NEXT_RELATIONSHIP.intValue();
// [...]
Passons sur le formatage digne des codeurs C les plus chevronnés (qui pour une Pull Request pour remettre les accolades en fin de ligne ? :P).
Ce qui est vraiment intéressant ici, c’est cette notion de first et
second. En réalité, il s’agit des références internes (tout est
référence à ce niveau) aux enregistrements correspondant aux noeuds de
départ et d’arrivée. Seulement, la notion de direction n’ayant de sens
qu’au moment du requêtage et non à la création de la relation, on ne
peut pas savoir, à ce niveau, qui du first ou du second est le noeud
de départ d’où cette nomenclature.
Ce que vous devez comprendre de ce petit bout de code, c’est qu’une relation porte en réalité, outre les informations précédemment mentionnées :
-
une référence vers ses noeuds de départ et d’arrivée
-
une référence vers la précédente relation des noeuds de départ / d’arrivée
-
une référence vers la relation suivante des noeuds de départ / d’arrivée
Une illustration vaut mieux qu’un long discours :
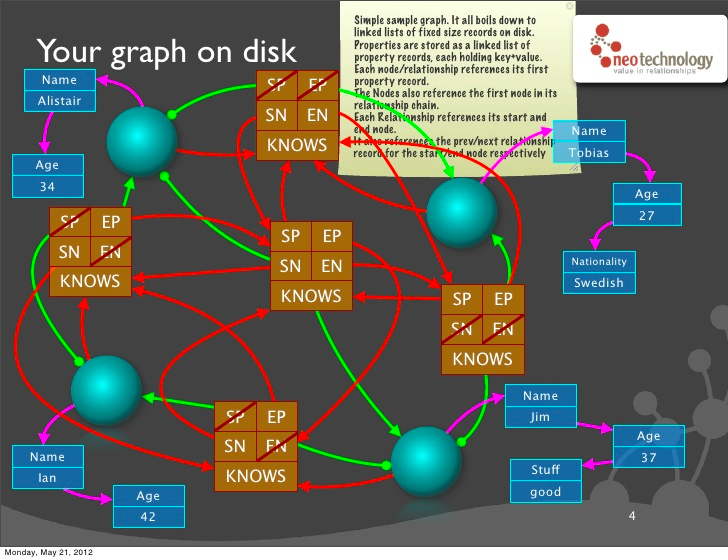
Il s’agit exactement de ce que j’ai tenté d’expliquer : les flèches rouges symbolisent les liens portés par les enregistrements de relations. Chacune de ces relations pointe vers les relations précédentes/suivantes de ses noeuds de départ et d’arrivée.
Autrement dit, chaque noeud référence (flèche verte) un élément d’une liste doublement chaînée de relations.
Et c’est là la nature même du graphe !
C’est par cette structure que Neo4j peut se targuer d’être une base de données graphe.
-
Comment requêter de la donnée dans un graphe ? Par une traversée.
-
Comment traverser dans Neo4j ? En trouvant les points de départ les plus pertinents possible et en naviguant dans listes de relations/noeuds.
Vous commencez à comprendre pourquoi ce genre de base de données s’adapte très bien aux données fortement connectées ?
Quid des noeuds denses ?
Ahah, je vois que j’ai affaire à des lecteurs initiés ;)
Resituons le contexte au travers de deux situations légèrement différentes.
Situation n°1
Un noeud dense est un noeud qui est fortement connecté. De nombreux exemples se retrouvent d’ailleurs dans la vie courante. Par exemple, Justin Bieber a 52 millions de followers sur Twitter (tiens, je ne savais pas que la surdité était devenu un phénomène de masse).
Rappelez-vous, le noeud Justin Bieber pointe vers sa première relation. Si par manque de chance, vous avez besoin d’accéder à son 52 millionième noeud-fan, vous allez devoir traverser, dans le pire des cas, l’intégralité de la liste doublement chaînée des relations avant de le retrouver : bref, du O(n)… vraiment pas terrible.
Ceci dit, ce cas reste relativement rare. Modifions légèrement l’exemple.
Situation n°2
Justin Bieber a certes 52 millions de followers mais il a bien moins de personnes dans sa famille.
Si par hasard, parmi cette gigantesque quantité de relations, seules les relations familiales vous intéressent, vous faites face exactement au même problème que décrit ci-dessus… si vous utilisez une version de Neo4j antérieure à la version 2.1 de Neo4j.
Depuis cette version, les relations sont aussi discriminées par type, permettant ainsi de ne pas tomber dans cet écueuil. Un noeud est d’ailleurs considéré dense à partir de 50 relations par défaut (cf. “http://docs.neo4j.org/chunked/stable/kernel-configuration.html[dense node threshold]”).
Help! Je suis dans la situation n°1!
Si par malheur, et après exploration de toutes les alternatives (échantillonnage statistique etc), vous en concluez que vous ne pouvez faire autrement : rassurez-vous !
Tout d’abord, les équipes de Neo continuent de plancher et d’apporter des améliorations à ce sujet. Nous devrions donc voir quelques améliorations avec la v2.2.
De plus, une approche simple est déjà codée pour vous par l’excellent Max de Marzi.
L’idée de son extension est simple : elle va simplement ventiler les noeuds par niveau lors de chaque nouvelle insertion et les lire de façon transparente.
Voici donc un exemple de structure automatiquement créée par son extension :
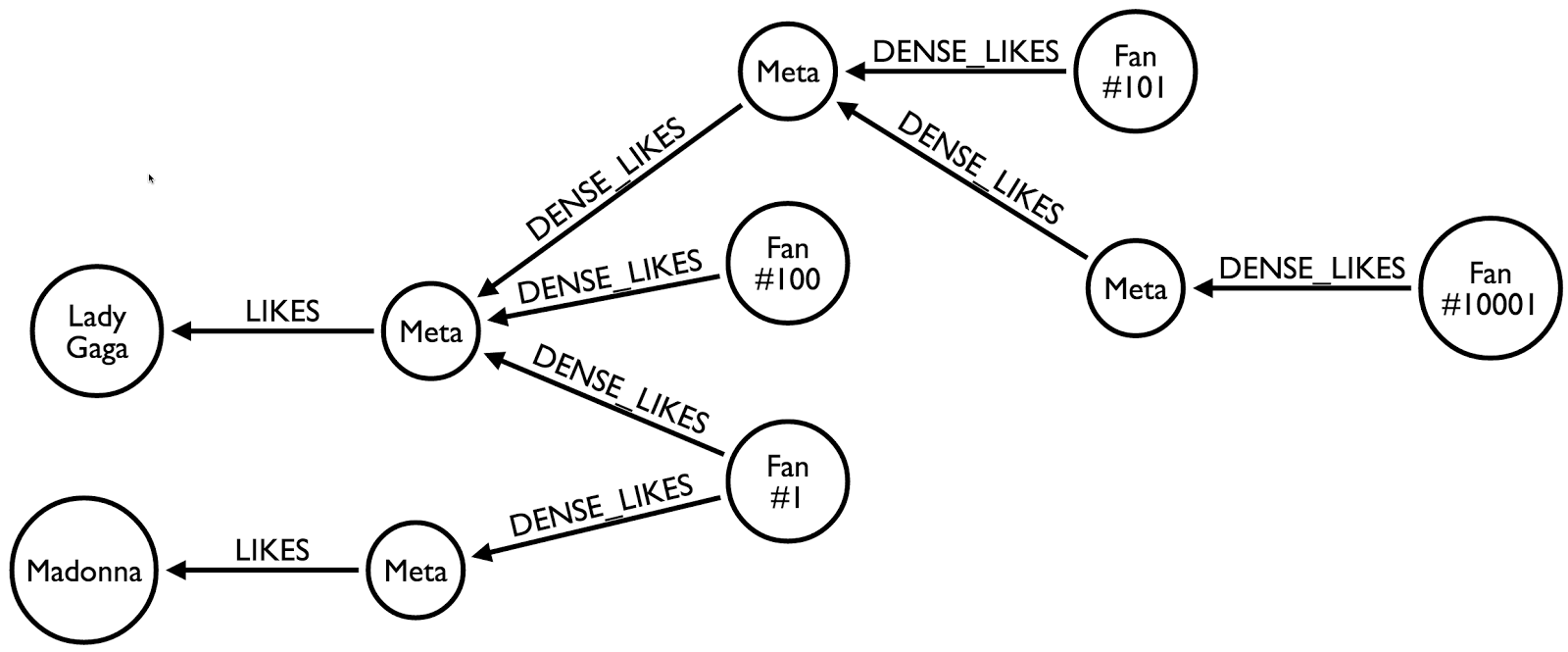
Tout comme Justin Bieber, Lady Gaga et Madonna ont également de nombreux fans (chaque fan “LIKES” l’artiste). Un noeud factice va donc se substituer aux noeuds que l’on aurait directement lié aux artistes et introduire des couches, par le biais de noeuds intermédiaires regroupant eux aussi un nombre limité de fans, relié alors par une “DENSE_LIKES”. Les relations sont maintenant réparties et l’on pourra paginer nos requêtes de lecture de cette façon :
MATCH (fan:Fan)-[:DENSE_LIKES*0..5]->()-[:LIKES]->(loved:Artist {name:
“Madonna”})
RETURN fan
Cette requête signifie (en lisant le pattern de bas en haut, de droite à gauche) :
retourne tous les noeuds au label “Artist” et au nom “Madonna” +
qui sont “LIKÉS“ par un noeud quelconque (appelons-le META) +
et 0 à 5 relations DENSE_LIKE séparent META des noeuds
Étant donné que la requête recherche les nombreux fans d’un artiste, sans aucune ventilation du graphe, nous serions en plein dans la situation n°1 décrite préalablement. Néanmoins, cette approche simple couplée à l’usage astucieux des variable-length paths permet de ne récupérer qu’une fraction des fans sans pour autant traverser toutes les relations dont l’artiste dépend.
Neo4j et scalabilité
Maintenant que le format physique des fichiers est un peu plus clair, regardons un peu les couches supérieures.
Architecture
Les accès disques sont bien évidemment limités autant que possible. Deux niveaux de cache interviennent.
Le file buffer cache
Vous vous en doutez, le file buffer cache sert de tampon aux écritures/lectures des enregistrements physiques (cf. les fichiers décrits précédemment). Les entrées les moins récemment accédées sont évincées du buffer (LRU). Si possible, ce buffer est directement mappé au fichier store sous-jacent (“memory-mapping”). Ce comportement dépend du système de fichiers et de l’OS. Quoi qu’il en soit, cette couche a pour seul but de réduire au maximum les accès disque mais n’introduit aucune forme d’abstraction sur les données manipulées.
L’object cache
Lui aussi cache LRU, c’est à partir de ce moment-là que les données manipulées commencent à prendre la forme du graphe que vous requêtez par traversée ou par Cypher. Notez que l’allocation mémoire à ce niveau est prise sur la heap de la JVM hôte et non plus directement de l’OS hôte sous-jacent. C’est pourquoi il est souvent préférable de déployer Neo4j de façon isolée, afin que votre application ne vienne pas perturber (comme par exemple : ) les cycles GC de votre instance Neo et vise-versa.
et le reste
À partir de là, les APIs unitaires Java prennent le relais, suivies des APIs de traversées, Cypher et les APIs REST !

Gestion de la concurrence
Bien que faisant partie de cette (non-)famille qu’est NoSQL, Neo4j fait un peu figure d’exception, en se conformant à ACID. En effet, vous retrouverez avec Neo4j les transactions en 2 phases que vous connaissez bien. N’étant pas un spécialiste des systèmes distribués, je vous invite à lire la multitude d’articles existants sur les limites d’ACID, les limites du locking et les alternatives existantes (“lock-free concurrency”, BASE vs ACID) : Google est votre ami. J’en profite donc pour passer à la partie qui m’intéresse le plus : le sharding :)
Sharding d’un graphe dynamique
Expliquons brièvement le terme sharding. Le sharding consiste simplement à répartir ses données entre différentes instances d’un système de persistence distribué. Par exemple : je peux décider de stocker toutes les adresses postales américaines sur mes serveurs aux États-Unis et mes adresses australiennes à Sydney. Une instance donnée ne contient donc pas l’intégralité des données, mais le domaine métier auquel appartient mon application appartient comporte des notions qui se répartissent naturellement. Eh oui ! Le sharding est une solution technique, certes, mais hautement dépendante du métier (comme toute solution technique devrait l’être, mais je digresse).
Graphe statique
Un graphe statique est plutôt facile à sharder (dans la mesure où le domaine métier modélisé le permet), ses fragmentations sont faciles à détecter (on parle de “graph clustering” ou de “community detection”) : elles ne sont pas amenées à évoluer du tout. Certains algorithmes sont même relativement faciles à implémenter.
Graphe dynamique
Pour les graphes dynamiques, en revanche, c’est une autre paire de manche. De nombreuses opérations d’insertion et suppression interviennent en permanence et elles impactent nécessairement la topologie du graphe. Le but du jeu est donc de déterminer un découpage du graphe en shards de telle sorte, qu’à tout instant, le nombre de relations inter-shards soit minimisé. Cela est d’autant plus critique que les shards sont distants (imaginez la latence réseau induite par une traversée qui commence par un shard hébergé à Los Angeles pour finir dans un shard à Pékin).
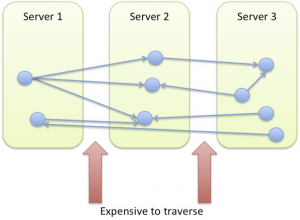
C’est un sujet de recherche à part entière et Neo Technology travaille depuis plusieurs années sur un système shardable. Comprenez bien le terrible dilemne : par son orientation graphe dès les couches physiques, Neo4j est à la fois idéal pour stocker et requêter des données sous forme de graphe mais également très difficile à sharder !
Une lueur d’espoir ?
- Il est pour l’instant nécessaire de miser sur du [*scaling
- vertical*](http://fr.wikipedia.org/wiki/Scalability) : dimensionnez
- suffisamment vos machines et tout se passera très bien. Laissez-moi vous
- rassurer davantage : * jusqu’à présent, une infime minorité de clients
- a été confrontée à une volumétrie telle ([capacité nomimale de
- Neo4j](http://docs.neo4j.org/chunked/stable/capabilities-capacity.html)
- 34 millards de noeuds et de relations) qu’une répartition des données était nécessaire * il se trouve que certains domaines métiers permettent naturellement de ségréguer ses données * il existe un début de solution de répartition !
Le cache sharding !
Le titre peut faire peur, mais rassurez-vous, l’idée est toute simple. Tout d’abord, cette idée s’applique à Neo4j en mode High Availability. En d’autres termes, cela ne s’applique qu’à une instance Neo4j au sein d’un cluster.
Non seulement vous bénéficiez d’une réplication master/replica, mais vous pouvez également bénéficier de sharding. Oui, oui, j’ai bien dit sharding. Malheureusement, pour les raisons évoquées plus haut, il ne s’agit pas de sharding sur les données à proprement parler. Comme le titre l’évoque, il s’agit de sharding sur le cache.
Comment est-ce possible ? C’est tout simple !
Les caches de Neo4j sont des caches LRU, ils ne conservent que les entrées les plus récentes en leur sein. S’il existait un moyen de répartir les requêtes de façon persistante entre chaque instance de mon cluster, le tour serait joué. En effet, la requête X serait toujours exécutée sur l’instance A, la requête Y sur l’instance B… Le résultat X serait de facto dans les caches A, celui d’Y dans les caches B. Mes données seraient donc effectivement réparties par cache. Le problème se réduit donc à : comment répartir de façon consistante les requêtes à exécuter entre les instances de mon cluster Neo4j ? Je vous le donne en mille. La solution existe depuis des lustres : un simple load balancer comme HAProxy saura faire l’affaire. On parle de consistent routing (plus généralement de consistent hashing). Il suffit de configurer sa façon de router selon un des arguments présents dans le corps ou un quelconque entête des appels HTTP envoyés à Neo (rappelez-vous : toute communication distante est définie par une API REST) et le load balancer se chargera d’exécuter vos ordres là où vous l’avez configuré ! Astucieux, non ? Un simple load balancer, un cluster Neo4j (l’édition High Availability vous fournit tous les outils qu’il vous fait) et vous êtes prêts à affronter une forte volumétrie de données !
Conclusion
Une des leçons de NOSQL est que toute solution se restreint à un certain champ d’application et s’applique sous certaines conditions. J’espère que cet article vous aura permis de comprendre les faiblesses mais surtout les forces des bases de données graphe et, qui sait, vous donnera envie d’approfondir le sujet.
Je ne prétends pas à l’exhaustivité, donc si vous souhaitez que je détaille d’autres parties (exemple : Cypher), je peux éventuellement y consacrer d’autres articles.
<shameless_plug>Si cet article vous a plu, je peux aussi venir en parler dans un User Group de votre ville et je donne des formations customisables sur Neo4j et en français ! </shameless_plug>